

Les nouvelles puces d’accélération d’IA boostent la mémoire HBM
Selon TrendForce, le produit dominant du marché HBM (High Bandwidth Memory) en 2023 est le HBM2e, employé par les NVIDIA A100/A800, AMD MI200 et la plupart des puces d’accélération d’IA auto-développées par les fournisseurs de services cloud (CSP ou FSC).
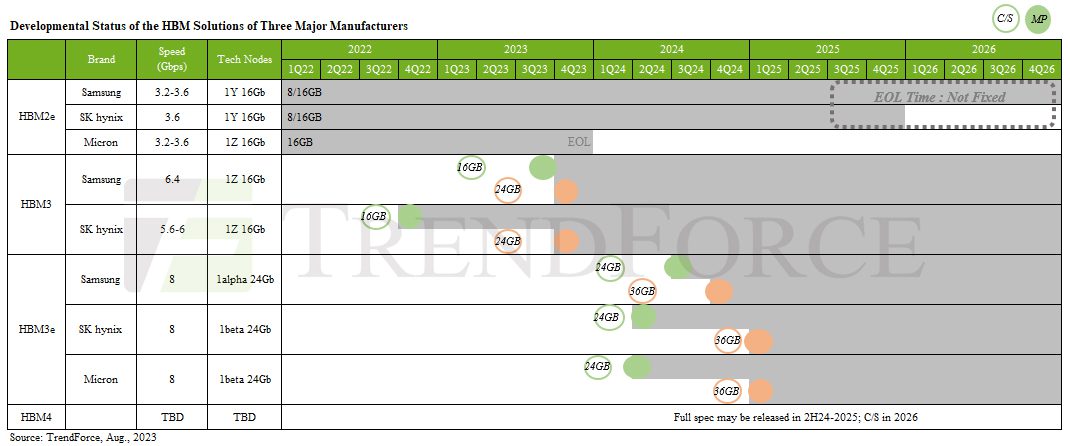
La demande de puces d’accélération pour l’IA évoluant, les fabricants prévoient d’introduire de nouveaux produits HBM3e en 2024, HBM3 et HBM3e devant se généraliser sur le marché l’année prochaine.
Les différences entre les générations de HBM se situent principalement au niveau de la vitesse. L’industrie a connu une prolifération de noms déroutants lors de la transition vers la génération HBM3. TrendForce précise que ce que l’on appelle HBM3 sur le marché actuel devrait être subdivisé en deux catégories basées sur la vitesse. La première catégorie comprend le HBM3 fonctionnant à des vitesses comprises entre 5,6 et 6,4 Gbps, tandis que la seconde comprend le HBM3e à 8 Gbps, qui porte également plusieurs noms, notamment HBM3P, HBM3A, HBM3+ et HBM3 Gen2.
L’état de développement de la mémoire HBM par les trois principaux fabricants, SK hynix, Samsung et Micron, est variable. SK hynix et Samsung ont commencé leurs efforts avec HBM3, qui est utilisé dans les produits H100/H800 de NVIDIA et la série MI300 d’AMD. Ces deux fabricants devraient également présenter des échantillons de HBM3e au premier trimestre 2024. Entre-temps, Micron a choisi d’ignorer le HBM3 et de développer directement le HBM3e.
HBM3e sera empilé avec des puces mono de 24 Gb, et sous la fondation 8 couches (8Hi), la capacité d’un seul HBM3e passera à 24 GB. Cette technologie devrait être intégrée dans le GB100 de NVIDIA, dont le lancement est prévu en 2025. Par conséquent, les principaux fabricants devraient avoir des échantillons de HBM3e au premier trimestre 2024 et viser une production de masse d’ici le deuxième semestre 2024.
Les FSC développent leurs propres puces d’IA afin de réduire leur dépendance à l’égard de NVIDIA et d’AMD.
NVIDIA continue de détenir la plus grande part de marché en ce qui concerne les puces d’accélération des serveurs d’IA. Toutefois, les coûts élevés associés aux GPU H100/H800 de NVIDIA, dont le prix varie entre 20 000 et 25 000 dollars l’unité, associés à la configuration à huit cartes recommandée pour les serveurs d’IA, ont considérablement augmenté le coût total de possession. Par conséquent, si les CSP continueront à s’approvisionner en GPU pour serveurs auprès de NVIDIA ou d’AMD, ils prévoient parallèlement de développer leurs propres puces d’accélération d’IA.
Les géants de la technologie Google et Amazon Web Services (AWS) ont déjà réalisé des avancées significatives dans ce domaine avec la création du processeur Google Tensor Processing Unit (TPU) et des puces AWS Trainium et Inferentia. En outre, ces deux leaders de l’industrie travaillent déjà d’arrache-pied sur leurs puces d’accélération de l’IA de la prochaine génération, qui devraient utiliser la technologie HBM3 ou HBM3e. En outre, d’autres CSP en Amérique du Nord et en Chine procèdent également à des vérifications connexes, ce qui laisse présager une intensification de la concurrence sur le marché des puces d’accélération d’IA dans les années à venir.
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :






