
1400 coeurs RISC-V pour l’apprentissage automatique sur une puce
Untether AI au Canada a développé un composant d’IA avec plus de 1400 processeurs RISC-V appelé Boqueria pour le calcul « en mémoire ».
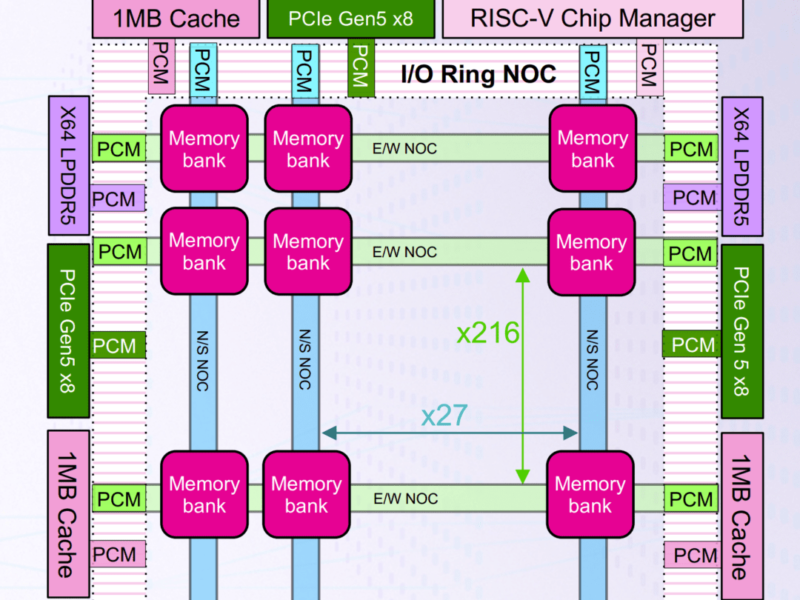
Boqueria, présenté lors de la conférence HotChips, est construit sur le process 7 nm de TSMC avec 238 Mo de SRAM. Le multi processeur a une performance de 2 PetaFlops pour les types de données AI FP8 8 bits avec une puissance de 30 TFLOPs/W qui vient du maintien du calcul au plus près des cœurs AI avec 729 banques de mémoire RISC-V doubles.
Étant donné que le calcul en mémoire est nettement plus économe en énergie que les architectures von Neumann traditionnelles, davantage de TFlops peuvent être effectués pour une enveloppe de puissance donnée. Avec l’introduction des composants runAI en 2020, Untether AI a vu un niveau d’efficacité énergétique à 8 TOPs/W pour le type de données INT8.
Autres articles IA
-
Microchip va développer une nouvelle génération de processeurs 12 core RISC-V pour la NASA
- CEO interview: Untether’s Arun Iyengar on the chiplet opportunity
- 48 core neuromorphic AI chip uses resistive memory
L’architecture speedAI utilisée dans Boqueria améliore encore cette performance, fournissant 30 TFlops/W. Cette efficacité énergétique est le produit de l’architecture de calcul en mémoire de deuxième génération, de plus de 1 400 processeurs RISC-V optimisés avec des instructions personnalisées, d’un flux de données économe en énergie et de l’adoption d’un nouveau type de données FP8, qui contribuent tous à une efficacité quadruple par rapport à runAI de génération précédente.
Chaque banque de mémoire de l’architecture speedAI dispose de 512 éléments de traitement avec une connexion directe à la SRAM dédiée. Ces éléments de traitement prennent en charge les types de données INT4, FP8, INT8 et BF16, ainsi que des circuits de détection de zéro pour l’economie d’énergie et la prise en charge de la parcimonie structurée 2:1.
Disposé en 8 rangées de 64 éléments de traitement, chaque rangée a son propre contrôleur dédié et une fonctionnalité de réduction câblée pour permettre une flexibilité dans la programmation et un calcul efficace des fonctions de réseau de transformateur telles que Softmax et LayerNorm. Les rangées sont gérées par deux processeurs RISC-V avec plus de 20 instructions personnalisées conçues pour l’accélération de l’inférence. La flexibilité de la banque de mémoire lui permet de s’adapter à une variété d’architectures de réseaux neuronaux, y compris les réseaux convolutifs, de transformateur et de recommandation ainsi que les modèles d’algèbre linéaire
Le premier membre de la famille, le speedAI240, fournit 2 PetaFlops de performance FP8 et 1 PetaFlop de performance BF16. Cela se traduit par des performances plus élevées, par exemple en exécutant le framework BERT à plus de 750 requêtes par seconde par watt (qps/w), 15 fois plus que l’état de l’art actuel des principaux GPU
Les recherches d’Untether AI ont déterminé que deux formats FP8 différents offraient le meilleur compromis pour la précision, la plage et l’efficacitéde fonctionnement. Une version à 4 mantisses (FP8p pour « précision ») et une version à 3 mantisses (FP8r pour « plage ») ont fourni la meilleure précision et le meilleur débit pour l’inférence sur une variété de réseaux différents. Pour les réseaux convolutionnels comme ResNet-50 et les réseaux de transformateurs comme BERT-Base, la mise en œuvre de FP8 par Untether AI entraîne moins de 1/10e de 1 % de perte de précision par rapport à l’utilisation des types de données BF16, avec une multiplication par quatre du débit et de l’efficacité énergétique. .
SpeedAI240 est conçu pour s’adapter à des modèles plus larges. L’architecture de la mémoire est à plusieurs niveaux, avec 238 Mo de SRAM dédiés aux éléments de traitement offrant 1 pétaoctet/s de bande passante mémoire, quatre blocs-notes de 1 Mo et deux ports larges de 64 bits de LPDDR5, fournissant jusqu’à 32 Go de DRAM externe.
Il existe 16 voies PCIe Gen5 pour la connectivité hôte à 63 Go/s avec trois ports PCIe Gen5 x8 pour la connectivité puce à puce et carte à carte, chacun fournissant 31,5 Go/s.
« Les mérites du calcul en mémoire ont été prouvés avec le dispositif runAI de première génération, et l’architecture speedAI de deuxième génération améliore l’efficacité énergétique, le débit, la précision et l’évolutivité de notre offre », a déclaré Arun Iyengar, PDG d’Untether AI. « Les composants speedAI offrent une capacité inégalée par toute autre offre d’inférence sur le marché. »
Untether AI dispose d’un kit de développement logiciel (SDK) appelé imAIgine qui permet d’exécuter des réseaux à hautes performances, avec une quantification par bouton-poussoir, une optimisation, une allocation physique et un partitionnement multipuce. Le SDK imAIgine fournit également une boîte à outils de visualisation complète, un simulateur de cycle précis et une API d’exécution facilement intégrée et est disponible dès maintenant.
Les composants speedAI seront proposés sous forme de puces autonomes ainsi qu’une variété de cartes dans un facteur de forme m.2 et PCI-Express. L’échantillonnage des appareils et des cartes speedAI240 pour les clients à accès anticipé devrait commencer au premier semestre 2023.
Lire aussi:
-
Le premier processeur RISC-V commence à fonctionner en orbite
L’UE lance son programme spatial intégré à 13 milliards d’euros
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :