
SemiDynamics présente son NPU RISC-V tout-en-un
La société espagnole SemiDynamics a mis au point une unité de traitement neuronal (NPU) IP entièrement programmable qui combine le traitement par CPU, vecteur et tenseur afin de fournir jusqu’à 256 TOPS pour les modèles de langage de grande taille et les systèmes d’IA.
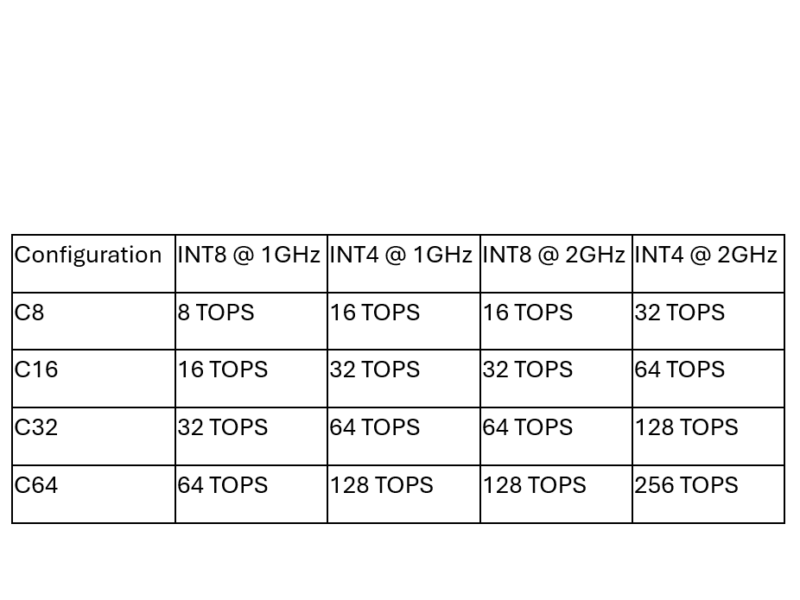
La NPU Cervell est basée sur l’architecture RISC-V à jeu d’instructions ouvert qui s’étend de 8 à 64 cœurs. Cela permet aux concepteurs d’adapter les performances aux exigences des applications, de 8 TOPS INT8 à 1 GHz pour les déploiements compacts edge à 256 TOPS INT4 pour l’inférence IA haut de gamme dans les puces de centres de données.
Elle fait suite au lancement de l’architecture tout-en-un en décembre dernier, détaillée dans ce livre blanc.
« Cervell est conçu pour une nouvelle ère de calcul de l’IA, où les solutions standard ne suffisent pas. En tant que NPU, il offre les performances évolutives nécessaires pour tout ce qui concerne l’inférence edge et les grands modèles de langage. Mais ce qui le distingue vraiment, c’est la façon dont il est construit : entièrement programmable, sans verrouillage grâce à l’ISA RISC-V ouverte, et profondément personnalisable jusqu’au niveau de l’instruction. Associé à notre sous-système de mémoire Gazillion Misses, Cervell élimine les goulets d’étranglement traditionnels des données et offre aux concepteurs de puces une base puissante pour construire des solutions d’IA différenciées et performantes », déclare Roger Espasa, PDG de Semidynamics.
- RISC-V AI IP sélectionné pour l’application LLM
- Le SDK RISC-V ajoute la prise en charge de l’exécution ONNX
- Une start-up espagnole pratique la chirurgie à cœur ouvert
Les NPU de Cervell sont spécialement conçues pour accélérer les opérations à forte intensité matricielle, ce qui permet d’augmenter le débit, de réduire la consommation d’énergie et d’obtenir une réponse en temps réel. En intégrant les capacités des NPU aux processeurs standard et au traitement vectoriel dans une architecture unifiée, les concepteurs peuvent éliminer la latence et maximiser les performances de diverses tâches d’IA, des systèmes de recommandation aux pipelines d’apprentissage en profondeur.
Les cœurs Cervell sont étroitement intégrés au sous-système de gestion de la mémoire Gazillion Misses. Cela permet d’effectuer jusqu’à 128 requêtes simultanées en mémoire, en éliminant les blocages de latence avec plus de 60 octets/cycle de flux de données continu. Il existe également un accès massivement parallèle à la mémoire hors puce, essentiel pour l’inférence de grands modèles et le traitement de données éparses.
Cela permet de maintenir une saturation totale du pipeline, même dans les applications gourmandes en bande passante telles que les systèmes de recommandation et l’apprentissage profond.
Le noyau est entièrement personnalisable avec la possibilité d’ajouter des instructions scalaires ou vectorielles, de configurer des mémoires scratchpad et des FIFO E/S personnalisées et de définir des interfaces mémoire et des schémas de synchronisation pour fournir un matériel d’IA différencié à l’épreuve du temps.
Cette personnalisation approfondie au niveau RTL, y compris l’insertion d’instructions définies par le client, permet aux entreprises d’intégrer la propriété intellectuelle unique directement dans la solution, protégeant ainsi leur investissement ASIC contre l’imitation et garantissant que la conception est entièrement optimisée en termes de puissance, de performance et de surface. Le modèle de développement comprend des chutes de FPGA précoces et une vérification parallèle afin de réduire le temps de développement et les risques.
|
Configuration |
INT8 @ 1GHz |
INT4 à 1 GHz |
INT8 à 2 GHz |
INT4 à 2 GHz |
|
C8 |
8 TOPS |
16 TOPS |
16 TOPS |
32 TOPS |
|
C16 |
16 TOPS |
32 TOPS |
32 TOPS |
64 TOPS |
|
C32 |
32 TOPS |
64 TOPS |
64 TOPS |
128 TOPS |
|
C64 |
64 TOPS |
128 TOPS |
128 TOPS |
256 TOPS |
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :





