
Intel obligé de modifier la feuille de route de ses GPUs pour supercalculateurs
Intel a dû abandonner sa dernière puce GPU car les clients de superordinateurs exigent une plus grande intégration des accélérateurs d’IA.
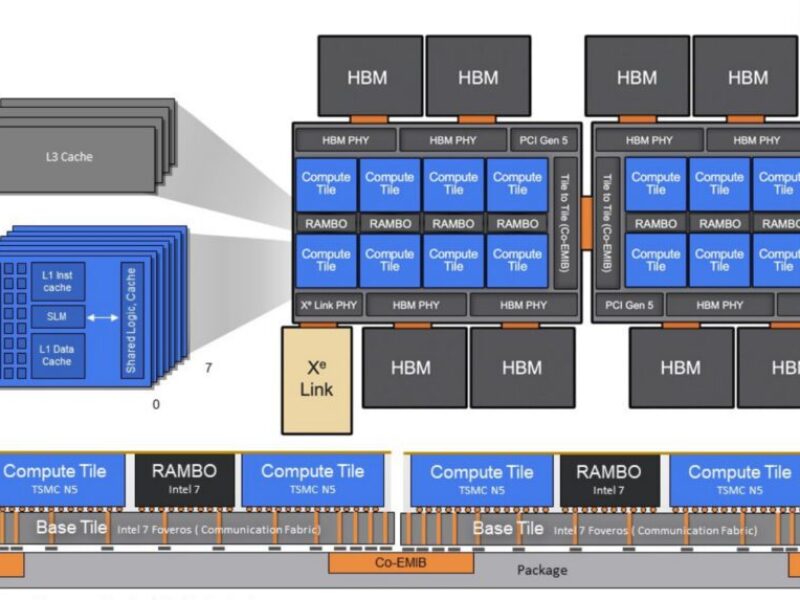
La société devait lancer son GPU Rialto Bridge plus tard cette année en tant que successeur commercial à coût réduit de sa très complexe puce Ponte Vecchio haut de gamme.
Cependant, la demande des clients de supercalculateurs et de centres de données a poussé Intel à abandonner cela et à se concentrer sur une nouvelle architecture, appelée Falcon Shores, qui combinera différents chiplets, et même des accélérateurs d’autres sociétés, en utilisant le modèle Intel Foundry (IDM) qui se base sur le Process de fabrication Intel 18 avec géométries de 1,8 nm.
- Intel launches its chiplet-based CPU and GPU families
- Ponte Vecchio 3D supercomputer processor uses five process nodes
- Intel shows engineering silicon of its biggest ever ‘chip’
« Nous avons simplifié notre feuille de route dans le but de faire moins de choses mais mieux », a déclaré Jeff McVeigh, vice-président et directeur général par intérim du groupe Accelerated Computing Systems and Graphics chez Intel.
Prévues pour une introduction en 2025, il y aura des variantes de Falcon Shores pour l’IA, le HPC et la convergence de ces marchés. Cela aura la flexibilité d’intégrer de nouvelles IP, y compris des cœurs de processeur et d’autres chiplets d’Intel et de clients au fil du temps, fabriqués à l’aide du modèle IDM 2.0.
Le GPU « Rialto Bridge » qui était destiné à fournir des améliorations progressives par rapport à notre architecture actuelle, sera abandonné », a-t-il ajouté.
Il a souligné le lancement en janvier des processeurs Xeon Scalable de 4e génération, Xeon CPU Max Series et Ponte Vecchio en tant que Data Center GPU Max Series. Mais il met également en évidence la série Data Center GPU Flex pour l’inférence IA et le processeur d’apprentissage en profondeur Habana Gaudi2 pour l’apprentissage.
« Le calcul accéléré et les GPU font partie des segments du marché informatique qui connaissent la croissance la plus rapide et sont au cœur du succès à long terme d’Intel. Nous constatons un excellent support client et nous continuons à démontrer d’énormes améliorations de performances dans les charges de travail HPC et IA du monde réel sur ces produits récemment déployés », a-t-il déclaré.
Les clients incluent le laboratoire national d’Argonne, qui déploiera plus de 60 000 GPU de la série Max et 20 000 CPU de la série Max pour alimenter le supercalculateur Aurora plus tard cette année. Aurora devrait devenir le premier supercalculateur au monde avec 2 exaflops de performances de pointe d’ici le troisième trimestre de 2023.
Il fournit également les laboratoires nationaux Lawrence Livermore (LLNL) et Sandia National Laboratories ainsi que le laboratoire national Los Alamos (LANL). Tout ces super calculateurs prennent plusieurs années à concevoir et à construire.
« Grâce à un engagement étroit avec les pour comprendre leurs besoins, nous simplifions et rationalisons la feuille de route GPU pour centre de données. Dans le but de maximiser le retour sur investissement pour les clients, nous passerons à une cadence de développement de deux ans pour les GPU des centres de données. Cela correspond aux attentes des clients concernant le lancement de nouveaux produits et leur laisse le temps de développer leurs écosystèmes », a-t-il déclaré. La famille de produits Flex Series passera également à une cadence de deux ans.
« Nous allons arrêter le développement de Lancaster Sound, qui devait être une amélioration progressive par rapport à notre génération actuelle. Cela nous permet d’accélérer le développement de Melville Sound qui constituera un saut architectural significatif par rapport à la génération actuelle en termes de performances, de fonctionnalités et de charges de travail qu’il permettra », a-t-il déclaré.
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :






