
Cœur RISC-V 4 voies personnalisable pour le big data
Semidynamics, en Espagne, a mis au point un noyau RISC-V 64 bits à 4 voies personnalisable pour les puces des centres de données.
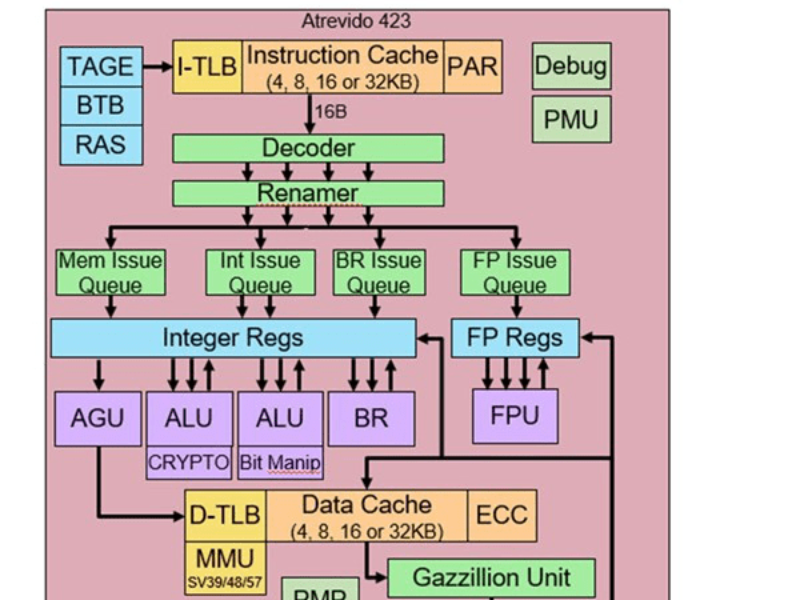
Le noyau RISC-V Atrevido 423 possède un large pipeline à 4 voies pour le décodage et le retrait de deux fois plus d’instructions que le noyau 223 à 2 voies précédent. Il est également couplé à un plus grand nombre d’unités fonctionnelles, ce qui augmente considérablement le débit d’instructions par cycle (IPC).
Atrevido peut être configuré comme un cœur cohérent avec un NoC CHI ou comme un cœur incohérent plus simple connecté via une interface AXI. Grâce à une TLB et une MMU améliorées et à la prise en charge des SV39/48/57, le noyau est bien adapté à l’exécution d’applications utilisant Linux avec de grandes empreintes de mémoire.
Le noyau Out-Of-Order est livré avec un large menu d’extensions RISC-V qui peuvent être ajoutées. Il peut notamment être configuré avec l’unité vectorielle interne, qui prend entièrement en charge la dernière spécification vectorielle RISC-V.
La clé de la personnalisation est une grande unité vectorielle avec jusqu’à 2048b de calcul par cycle pour le traitement des données. L’unité vectorielle est composée de plusieurs « cœurs vectoriels », à peu près équivalents à un cœur de GPU, qui effectuent plusieurs calculs en parallèle. Chaque noyau vectoriel possède des unités arithmétiques capables d’effectuer des opérations d’addition, de soustraction, de multiplication-addition fusionnée, de division, de racine carrée et des opérations logiques.
Le noyau vectoriel peut être adapté pour prendre en charge différents types de données : FP64, FP32, FP16, BF16, INT64, INT32, INT16 ou INT8, en fonction du domaine d’application visé par le client. La plus grande taille du type de données en bits définit la largeur du noyau du vecteur ou ELEN. Les clients choisissent ensuite le nombre de cœurs vectoriels à mettre en œuvre dans l’unité vectorielle, soit 4, 8, 16 ou 32 cœurs, ce qui permet d’obtenir un très large éventail d’options de compromis entre puissance, performances et surface. Une fois ces choix effectués, la largeur totale du chemin de données de l’unité vectorielle, ou DLEN, est égale à ELEN x nombre de cœurs vectoriels. Semidynamics supporte les configurations DLEN de 128b à 2048b.
Le cœur offre également un deuxième choix clé dans l’unité vectorielle : le nombre de bits de chaque registre vectoriel (connu sous le nom de VLEN) peut également être adapté aux besoins du client. Alors que la plupart des autres fournisseurs partent du principe que le VLEN est égal au DLEN (c’est-à-dire un rapport de 1X), Semidynamics propose des rapports de 2X, 4X et 8X. Lorsque le VLEN est plus grand que le DLEN, l’exécution d’une opération vectorielle nécessite plusieurs cycles. Par exemple, lorsque VLEN=2048 et DLEN=512, l’exécution de chaque opération arithmétique vectorielle prend quatre horloges. Il s’agit d’une fonctionnalité très utile pour tolérer des temps de latence importants dans la mémoire et pour réduire la consommation d’énergie.
Les autres extensions sont la manipulation de bits, la cryptographie, les FP en simple précision, les FP en double précision et les FP en demi-précision, ainsi que bfloat16. Les clients peuvent également choisir de protéger le cache de données avec ECC et le cache d’instructions avec parité, si cela est nécessaire pour leurs marchés cibles. En outre, le cœur d’Atrevido est entièrement conforme au dernier profil RISC-V RVA22. Les noyaux ne dépendent pas du process de fabrication, des versions étant déjà fournies jusqu’à 5 nm.
« L’Atrevido 423 est particulièrement bien adapté aux applications qui requièrent des quantités massives de données. Il brille lorsque les données requises ne peuvent pas être stockées dans des niveaux de hiérarchie de mémoire plus proches du cœur (tels que L1, L2 ou même L3) en tolérant de très grandes latences sans compromettre le débit grâce à notre technologie Gazzillion misses », a déclaré Roger Espasa, PDG de Semidynamics.
« Il peut traiter jusqu’à 128 demandes simultanées de données et les suivre jusqu’au bon endroit, quel que soit l’ordre dans lequel elles sont renvoyées. Gazzillion permet au cœur d’accéder à des niveaux hiérarchiques de mémoire très éloignés du cœur sans impact sur la bande passante ou le débit. En effet, la technologie Gazzillion élimine les problèmes de latence qui peuvent survenir lors de l’utilisation de la technologie CXL pour permettre à la mémoire éloignée d’être accédée aux taux suralimentés qu’elle a été conçue pour fournir. Atrevido est ainsi très bien positionné pour gérer les charges de travail d’IA et de HPC, qui ont généralement besoin d’accéder rapidement à de très grandes quantités de données à partir de la mémoire principale. »
L’extension cryptographique scalaire mise en œuvre suit la dernière spécification (Zks et Zk) et fournit un chiffrement de haute performance pour des algorithmes tels que SHA2-256, SHA2-512, ShangMi 3, ShangMi 4, AES-128, AES-192, et AES-256. L’implémentation en temps constant de l’Atrevido 423 offre une sécurité contre les attaques par canal latéral tout en fournissant une solution cryptographique de haute performance.
« Semidynamics possède les cœurs les plus rapides du marché pour déplacer de grandes quantités de données avec une ligne de cache par horloge à des fréquences élevées, même lorsque les données ne tiennent pas dans le cache. Et cela peut se faire à des fréquences allant jusqu’à 2,4 GHz sur le bon nœud. Le reste du marché propose en moyenne une ligne de cache tous les très nombreux cycles, ce qui est loin d’être le cas de Semidynamics, qui propose une ligne de cache par cycle », a déclaré M. Espasa.
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :






