Nouvelle architecture IA pour le GPU Imagination E-series
Imagination Technologies intègre des cœurs de traitement d’IA simplifiés dans sa dernière unité de traitement graphique (GPU) de la série E, plutôt que d’ajouter un accélérateur ou un coprocesseur d’IA.
La propriété intellectuelle de la série E a été développée pour les puces destinées aux smartphones, à l’automobile et aux PC d’intelligence artificielle, où l’intelligence artificielle peut être utilisée parallèlement au rendu graphique.
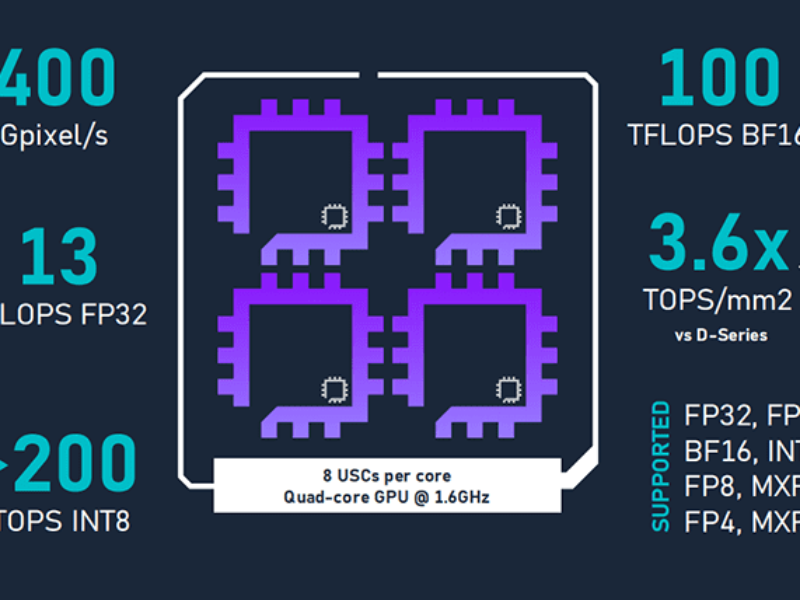
Le traitement distribué permet à Imagination d’utiliser son rendu basé sur les tuiles, efficace en termes de mémoire, et de le transformer en » calcul basé sur les tuiles » pour une gestion de la mémoire et un traitement plus efficaces. Cela permet d’obtenir 13 TFLOPS avec des instructions en virgule flottante 32 bits FP32 pour des performances supérieures à 200 TOPS. C’est 3,6 fois plus de TOPS/mm2 que les précédents GPU de la série D.
Imagination avait développé un coprocesseur NPU (Neural Processing Unit) pour accompagner ses CPU, mais a récemment mis fin à ces deux lignes de produits.
« La principale chose dont nous nous sommes rendu compte précédemment avec un NPU dédié était que les progrès se situaient au niveau des algorithmes, tels que les modèles de transformateurs. Plus nous nous penchons sur cet espace, plus les améliorations sont logicielles, et cela reste un problème de calcul parallèle », explique Kristof Beets, vice-président de la gestion des produits chez Imagination, à eeNews Europe.
- La série B 3 nm vise l’IA dans les centres de données
- Imagination se retire des processeurs RISC-V
- Le PDG d’Imagination doit démissionner, selon un tribunal chinois
« Si l’on considère les points d’équilibre, le CPU est essentiellement un moteur séquentiel et il a donc du mal à être efficace. Tant que vous restez sur le chemin rapide, ce pour quoi il est conçu, le NPU est époustouflant, mais là où il échoue, c’est au niveau de l’évolutivité et de la flexibilité, car beaucoup de NPU n’ont pas de capacités de programmation.
« C’est la raison pour laquelle nous revenons toujours à la solution GPU. Plus nous l’examinons, plus nous constatons qu’il s’agit de la meilleure solution universelle en termes d’évolutivité. Nous prenons donc les astuces qui fonctionnent pour le NPU et les transposons dans le cadre du GPU ».
« Nous avons réalisé que la plupart des optimisations pour l’IA sont des algorithmes basés sur les tuiles, de sorte que notre rendu basé sur les tuiles devient un calcul basé sur les tuiles. De la même manière, notre rendu différé devient un calcul différé, car l’élagage et la prise en charge des données éparses sont similaires. Un grand nombre de ces concepts clés peuvent être appliqués au matériel dont nous disposons déjà.
Nous prenons les astuces qui fonctionnent pour le NPU et les transposons dans le cadre du GPU – Kristof Beets
Les performances de l’architecture s’échelonnent de 2 à 200 TOP avec des opérations sur des nombres entiers à 8 bits.
« L’accent est mis sur l’intelligence artificielle et edge. Pour nous, edge est à peu près tout ce qui n’est pas le cloud, la formation au centre de données et l’inférence. Edge, c’est tout le reste, là où vous avez besoin de réactivité et de confidentialité », a déclaré M. Beets.
« Fondamentalement, il y a quelques cas d’utilisation où nous ne jouons pas, car nous sommes toujours fondamentalement un concepteur de GPU. S’il s’agit d’une simple IA avec un microcontrôleur dans les wearables ou l’IoT, ce n’est pas pour nous. Ce sont les smartphones graphiques et haut de gamme qui nous intéressent, de l’entrée de gamme au haut de gamme. L’automobile est également un marché solide pour nous et continue de croître, avec des dérivés dans la robotique.
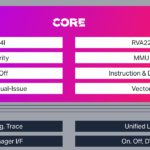
Architecture GPU de la série E
Elle utilise une nouvelle architecture qu’Imagination appelle « burst processors » (processeurs à rafales). Ceux-ci utilisent un pipeline de traitement simplifié en deux étapes qui opère sur les données de la mémoire locale sans nécessiter d’architecture de chargement/stockage.
« Il y a beaucoup d’adressage direct plutôt que de chargement et de stockage avec un accès direct à la mémoire locale », a déclaré M. Beets. « Le pipeline plus court contribue à l’exécution des instructions et à l’efficacité énergétique. Peu importe qu’il s’agisse de graphisme, de calcul ou d’intelligence artificielle.
Cela permet de réutiliser beaucoup plus de données. « L’IA s’appuie très souvent sur les données des instructions précédentes », explique M. Beets.
« L’autre chose, c’est que vous échangez des données avec vos voisins. Ainsi, en passant d’un pipeline à l’autre, nous pouvons garder toutes les données actives dans une mémoire locale plus petite. Nous touchons donc 60 % moins de registre en échangeant des données localement. La seule solution est l’intégration profonde en tant que pipeline dans le cluster de nuanceurs universel (USC), où nous pouvons réutiliser la SRAM », a-t-il déclaré. Il y a 500 Ko par USC et 128 Ko par USC de mémoire locale pour le streaming.
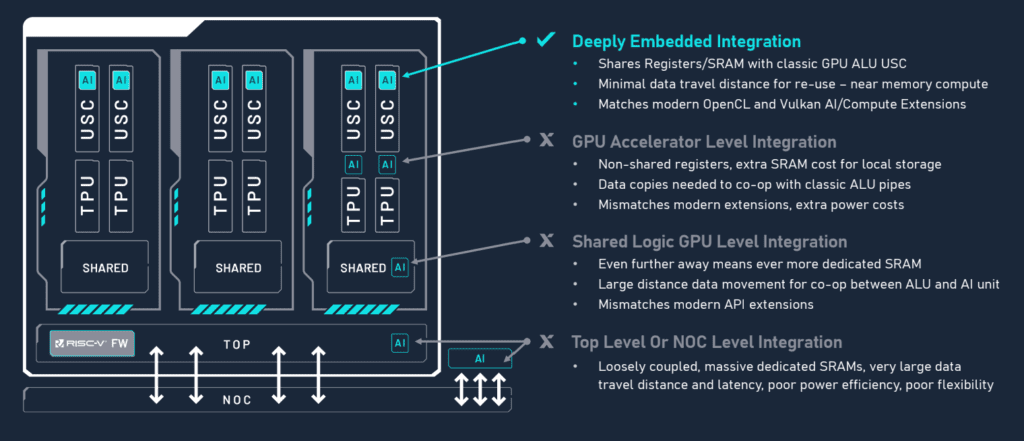
L’architecture distribuée de l’IA a un impact sur l’interconnexion des cœurs de traitement. Elle détermine le nombre de blocs de traitement qui peuvent être mis en œuvre, en maintenant les fils à une longueur qui permet une opération à cycle unique, ou « pipeline rapide ».
« Nous fournirons la bibliothèque et écrirons l’algorithme pour rester dans le pipeline rapide », a déclaré M. Beets. « Nous résolvons le problème de la synthèse avec cette fenêtre rapide à distance limitée et nous nous rabattons sur un mécanisme secondaire, plus lent, si nécessaire.
« Nous avions l’habitude de prendre en charge 8 machines virtuelles, maintenant il y en a 16 par cœur, donc 64 dans une implémentation à quatre cœurs. Nous prenons en charge tous les différents mécanismes avec un hyperviseur ou un bac à sable, et nous avons développé cela depuis la série B. »
Mise en œuvre de la série E
Il y a huit USC par cœur, et une implémentation GPU quadruple cœur fonctionne à 1,6 GHz.
La version EXT sera optimisée pour les smartphones, tandis que la version EXS ajoutera la sécurité fonctionnelle pour la surveillance du conducteur et les puces de cockpit IA dans l’automobile, et la version EXD sera utilisée pour les modèles Windows AI avec l’IA locale et la confidentialité, ainsi que les interfaces vocales.
« Nous reconnaissons que les clients du secteur automobile ont des NPU personnalisées, mais ils demandent tous des optimisations pour le co-working, ce qui signifie que nous prenons en charge la SRAM partagée sur la puce, mais aussi un système de communication de boîte aux lettres pour que vous gagniez en flexibilité ».
Selon M. Beets, un client principal utilise l’architecture et la première configuration est prévue pour l’automne 2025. « Dans le passé, nous avons livré des solutions mobiles et de bureau au cours du second semestre, alors que l’automobile prend un peu plus de temps, car il faut procéder à la mise en œuvre et ajouter la sécurité fonctionnelle », a-t-il déclaré.
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :