
Les mathématiques du XVIIIe pour des modèles d’IA plus simples
Des chercheurs de l’université de Jyväskylä ont réussi à simplifier la technique la plus populaire de l’intelligence artificielle, l’apprentissage profond, en utilisant des mathématiques du XVIIIe siècle
L’apprentissage profond permet aux ordinateurs d’effectuer des tâches complexes telles que l’analyse et la production d’images et de musique, les jeux numérisés et, plus récemment, en relation avec ChatGPT et d’autres techniques d’IA générative, d’agir comme un agent conversationnel en langage naturel qui fournit des résumés de haute qualité des connaissances existantes.
Il y a six ans, le professeur Tommi Kärkkäinen et le chercheur doctorant Jan Hänninen ont mené des études préliminaires sur la réduction des données. Les résultats sont surprenants : Si l’on combine des structures de réseau simples d’une manière originale, la profondeur n’est pas nécessaire. Des résultats similaires, voire meilleurs, peuvent être obtenus avec des modèles peu profonds.
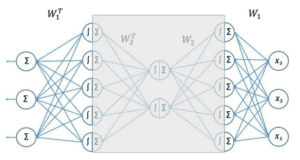
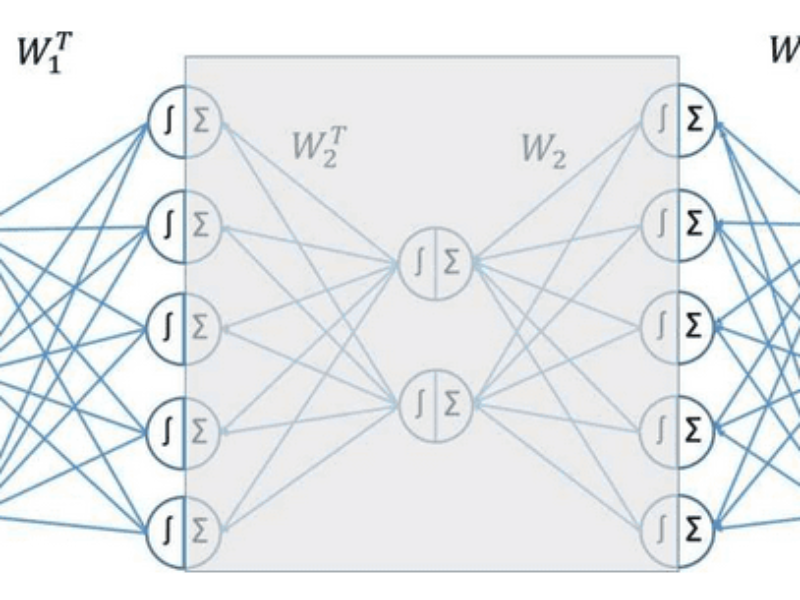
Pré-entraînement par couches, des têtes aux couches internes. La couche la plus externe est entraînée en premier et son résidu est ensuite utilisé comme données d’entraînement pour la couche cachée suivante, jusqu’à ce que toutes les couches aient été entraînées de manière séquentielle. Crédit : Neurocomputing (2023). DOI: 10.1016/j.neucom.2023.126520
« L’utilisation de techniques d’apprentissage profond est une entreprise complexe et sujette aux erreurs, et les modèles qui en résultent sont difficiles à maintenir et à interpréter », explique Kärkkäinen. « Notre nouveau modèle, dans sa forme superficielle, est plus expressif et peut réduire de manière fiable de grands ensembles de données tout en conservant toutes les informations nécessaires qu’ils contiennent ».
La structure de la nouvelle technique d’IA remonte aux mathématiques du XVIIIe siècle. Kärkkäinen et Hänninen ont également constaté que les méthodes d’optimisation traditionnelles des années 1970 fonctionnent mieux pour préparer leur modèle que les techniques du 21e siècle utilisées dans l’apprentissage profond.
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :







