

Le CNRS porte TinyML dans le calcul en mémoire analogique
Des chercheurs du CNRS ont développé une technologie pour utiliser les frameworks d’apprentissage automatique TinyML dans le calcul analogique en mémoire pour une IA embarquée à faible consommation
AnalogNAS peut être utilisé pour porter l’IA TinyML vers une mémoire à changement de phase analogique basse consommation dans des matrices de calcul de mémoire (IMC) pour une implémentation beaucoup plus simple d’applications d’IA telles que les mots de réveil ou la reconnaissance de signaux.
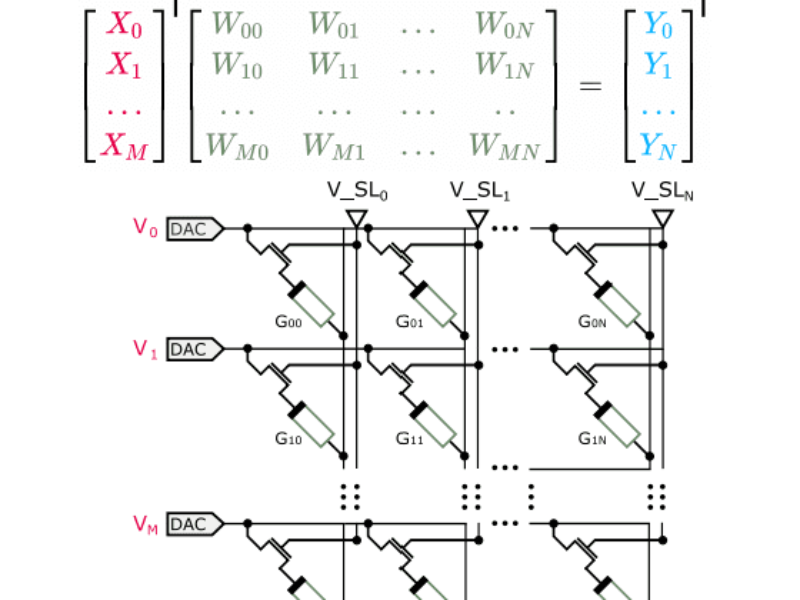
Les poids des couches DNN linéaires, convolutionnelles et récurrentes sont mappés sur des tableaux crossbar des éléments de mémoire non volatile (NVM). En exploitant les lois de circuit de base de Kirchhoff, les multiplications matrice-vecteur (MVM) peuvent être effectuées en codant les entrées sous forme de tensions et les poids Word-Line (WL) sous forme de conductances du composant. Pour la plupart des calculs, cela supprime le besoin de transmettre des données entre les unités centrales de traitement (CPU) et la mémoire.
Le framework fournit un déploiement automatisé de ciblage de conception DNN sur les accélérateurs d’inférence IMC et atteint une précision supérieure à celle des derniers modèles numériques sur une puce IMC à 64 cœurs basée sur la mémoire à changement de phase (PCM).
Hadjer Benmeziane du CNRS a travaillé avec des chercheurs d’IBM à Zurich, à New York et en Californie sur le développement du framework et d’une puce expérimentale.
Chaque cœur de la puce IMC à 64 cœurs se compose d’un réseau crossbar de 256×256 cellules unitaires PCM ainsi que d’une unité de traitement numérique locale. Deux réseaux pour la tâche de classification d’images CIFAR-10 ont été testés sur le matériel : AnalogNAS T500 et les réseaux de référence ResNet32#.
- In-memory computing startup launches to enable edge AI
- Compute-in-memory chip runs AI apps at fraction of the power
Le graphe d’inférence informatique de chaque réseau a été exporté et utilisé pour générer des flux de données propriétaires à exécuter en mémoire. Comme seule la validation de la précision du matériel était effectuée, toutes les autres opérations en dehors des MVM ont été effectuées sur une machine hôte connectée à la puce via un FPGA.
La précision matérielle mesurée était de 92,05 % pour le T500 et de 89,87 % pour le Resnet32, ce qui est nettement meilleur que le Resnet32 exécuté sur du matériel numérique.
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :




