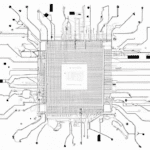
La plateforme d’IA générative basée sur les chiplets améliore les performances du LLM
Le fournisseur de technologies d’IA générative d-Matrix Inc. (Santa Clara, Californie) a annoncé Jayhawk II, une deuxième génération de sa plateforme de calcul d’IA générative.
Le nouveau silicium offre une version améliorée du moteur de calcul numérique en mémoire (DIMC) grâce à l’utilisation de l’interconnexion chiplet.
Le processeur basé sur des chiplets permet d’améliorer de 40 fois la bande passante de la mémoire par rapport aux GPU haut de gamme les plus récents, selon l’entreprise. d-Matrix affirme également que Jayhawk II peut ainsi traiter entre 10 et 20 fois plus d’inférences génératives par seconde pour des modèles de langage de grande taille (LLM) allant de 3 milliards à 40 milliards de paramètres, par rapport aux solutions GPU de pointe. Selon l’entreprise, cela se traduit par un coût total de possession 10 à 20 fois inférieur pour l’inférence générative par rapport à ces solutions GPU.
Le silicium démontre une architecture DIMC couplée à la norme d’interconnexion OCP Bunch of Wires (BoW) PHY pour l’inférence IA à faible latence sur les grands modèles de langage (LLM), des LLM à l’échelle du centre de données comme ChatGPT aux modèles plus ciblés comme Llama2 de Meta ou Falcon de l’Institut d’innovation technologique.
Le moteur DIMC, qui passe de 30 TOPS par watt à 150 TOPS par watt, est mis en œuvre dans un process de fabrication 6 nm. Le moteur prend en charge les types de données à virgule flottante et à virgule flottante par bloc dans toute une gamme de précisions. Il prend en charge les approches de compression et d’espacement permettant la mise en cache rapide des modèles génératifs d’IA.
Jayhawk II est maintenant disponible pour démonstrations et évaluations.
Liens et articles connexes :
Articles de presse :
d-Matrix retarde le processeur chiplet pour mieux répondre aux besoins de l’IA générative
SemiFive aide à mettre au point le processeur Chatbot, battu par Nvidia
La startup sud-coréenne Rebellions lance un processeur d’IA
Nvidia modifie la puce A100 pour se conformer aux règles américaines de contrôle des exportations
Un GPU chinois basé sur des puces établit un record de performance
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :