


Interview du CEO Efficient : processeur edge IA 100x plus efficace
Le concepteur de puces et de compilateurs Efficient Computer a fait la démonstration de son architecture de processeur d’IA à usage général très efficace.
Le code s’exécute sur une architecture « fabric » qui est un flux de données spécial optimisé pour l’efficacité énergétique et qui peut faire fonctionner un pipeline DSP à 1,3 TOPS/W pour l’IA edge. Elle repose sur une série de 256 tuiles qui constituent l’élément de traitement, chacune étant dotée d’une UAL et d’une logique permettant d’exécuter une seule instruction.
« Ce qui est fondamentalement différent, c’est que l’architecture a été développée avec un compilateur et une pile logicielle en même temps, à partir de recherches menées à Carnegie Mellon, et que nous l’avons conçue en gardant la généralité à l’esprit », explique Brandon Lucia, PDG et fondateur, à eeNews Europe/ ECInews.
Le compilateur génère une représentation du flux de données et place les instructions dans un réseau efficace sur la puce. Un cœur RISC-V configure le tissu et s’éteint ensuite pour laisser les tuiles fonctionner, bien que le « fabric » puisse se reconfigurer en tant que processeur à usage général capable d’exécuter C, C++ ou Rust, ainsi que des frameworks d’intelligence artificielle edge et potentiellement des frameworks de transformation.
« Nous n’avons pas besoin d’un flux de registres ni d’une recherche d’instructions à chaque cycle », a déclaré Luca. « Un sous-ensemble de tuiles sont également des tuiles d’accès à la mémoire – c’est une manière efficace de structurer la mémoire.
La société a levé 16 millions de dollars en mars dernier pour la phase suivante du développement.
- Efficient Computer lève 16 millions de dollars pour son architecture de processeur
- Selon un rapport américain, l’informatique économe en énergie nécessite de nouveaux dispositifs et de nouvelles architectures
- La nouvelle architecture de puce d’IBM permet d’envisager une puce plus rapide et plus économe en énergie
« Notre approche englobe le matériel et le logiciel, ce qui est la seule voie vers l’efficacité. Au lieu d’exécuter une série d’instructions comme les conceptions de von Neumann, notre architecture exprime les programmes sous la forme d’un « circuit » d’instructions qui montre quelles instructions communiquent entre elles. Ce modèle nous permet de répartir le circuit dans un réseau de processeurs extrêmement simples et d’exécuter le programme en parallèle, avec un matériel beaucoup plus simple (et donc moins d’énergie !) que n’importe quel processeur existant », a-t-il déclaré.
« Nous appelons cette conception l’architecture de processeur Fabric, et nous l’avons mise en œuvre dans le système sur puce (SoC) de l’essai Monza. Le compilateur du Fabric a été conçu en même temps que le matériel dès le premier jour, et il compile des programmes écrits en C ou C++ de haut niveau ».
La première puce a des performances de 1,3 à 1,5 TOPS/W, ce qui représente 500 à 600 mW pour la puce. « Si vous utilisez un plus petit nombre d’éléments de processeur, vous avez moins de puissance et vous pouvez donc optimiser la puissance pour la performance par le biais du compilateur ».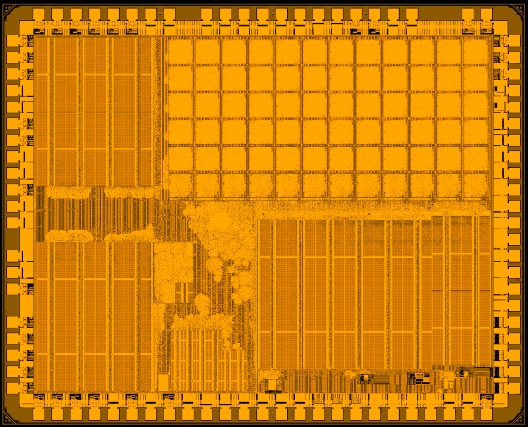
« Les ordinateurs d’aujourd’hui sont terriblement inefficaces. La conception dominante du processeur « von Neumann » gaspille 99 % de l’énergie. Cette inefficacité est malheureusement profondément ancrée dans leur conception. Dans les processeurs de von Neumann, les programmes sont exprimés sous la forme d’une séquence d’instructions simples, mais l’exécution de programmes dans une séquence simple est d’une lenteur inacceptable. L’amélioration des performances nécessite du matériel complexe pour trouver des instructions qui peuvent être exécutées en parallèle en toute sécurité », a-t-il déclaré.
« L’amélioration de l’efficacité nécessite de repenser fondamentalement la manière dont nous concevons les ordinateurs. D’autres ont abordé ce problème en restreignant les programmes, c’est-à-dire en limitant le processeur à l’exécution de programmes où le parallélisme est facile à trouver. Ces restrictions permettent aux concepteurs de simplifier et de spécialiser le matériel. Bien que cette approche améliore l’efficacité, elle renonce à la programmabilité générale, ce qui constitue un énorme problème.
« La généralité est synonyme d’efficacité : toute partie d’un programme qui fonctionne de manière inefficace limite rapidement l’efficacité énergétique de l’ensemble du système. De plus, ces processeurs spécialisés ne tiennent pas compte des logiciels, alors que c’est là que réside la véritable valeur de l’informatique.
Le compilateur prend actuellement en charge TensorFLowLite pour l’apprentissage automatique, et la prise en charge du format ONNX AI Framework est prévue. Il s’appuie sur la représentation intermédiaire multiniveaux (MLIR) développée dans le cadre de l’activité du compilateur LLVM afin d’offrir une certaine flexibilité.
« Nous avons construit le compilateur sur la pile de compilateurs MLIR, de sorte que nous prenons directement le flux TensorFlow existant et l’optimisons pour le Fabric – c’est vraiment puissant car nous pouvons prendre des langages intermédiaires tels que Rust et nous les prendrons en charge, ainsi que Python et Matlab », a déclaré Lucia.
« En ce qui concerne l’avenir, nous avons une feuille de route pour faire évoluer l’architecture au fur et à mesure que nous explorons l’espace de conception. Au début de l’année 2025, nous pourrons atteindre 100 GOPS à 200 MHz et nous pensons pouvoir multiplier les performances par 10 ou 100 avec la même efficacité.
Une partie de cette exploration porte également sur les structures de transformation pour les applications d’intelligence artificielle edge à faible consommation d’énergie. « S’il existe un transformateur qui s’adapte à la mémoire, nous pouvons le faire fonctionner, c’est quelque chose de très intéressant », dit-il.
www.efficient.computer ; mlir.llvm.org/
 Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :
Si vous avez apprécié cet article, vous aimerez les suivants : ne les manquez pas en vous abonnant à :







